안녕하세요! 제리입니다.
DMQA 김성범교수님 유튜브인 Time Series Regression (1)~(3) 강의를 보며 정리했습니다.
https://www.youtube.com/watch?v=7Do_hixXCpc
시계열 데이터 : 시간의 흐름에 따라 순서대로 관측되어 시간의 영향을 받게 되는 데이터로 일, 달, 분기, 년 등
구성 – 추세(trend), 순환(cycle), 계절(seasonal variations), 우연(random fluctuation)
추세 : 시간이 경과함에 따라 관측값이 지속적으로 증가하거나 감소하는 추세를 갖는 경우의 변동 (Downward, Upward)
순환, 주기 : 주기적인 변화를 가지거나, 계절에 의한 것이 아니고 주기가 긴 경우의 변동
계절 : 주별, 월별, 계졀별과 같이 주기적인 요인에 의한 변동, 순환 변동의 특정한 변동
우연 변동 : 규치적인 움직임과 무관하게 랜덤한 원인 (ex, 백색잡음 : 평균이 0이고 분산이 일정한 시계열 데이터)

맨위부터 observed, trend, seasonal, random => observed = trend+seasonal+random
예측 오차 : t시점에서의 실제값 – 예측값 => 작을수록 좋음, 오차의 부호가 중요하지 않고 정도가 중요하기에 단순히 더한 측도는 좋지 않음
평균절대편차(MAD) : 예측 오차를 절대값을 씌운 후 다 더하고 개수로 나눔
평균제곱편차 (MSE) : 절대값을 한 후 더해서 개수로 나눔
MAD vs MSE => 공통 : 모두 다 양수로 만듦
차이 : MSE의 경우 예측 오차의 차이가 크면 수가 점점 더 커진다는 점
MAPE(Mean Absolute Percentage Error) : 평균적으로 보여줌

실제값이 0이면 안됨, 실제값이 작으면 굉장히 커진다는 특징
예측값이 실제값보다 작을 경우 MAPE가 호의적으로 나옴
Y = 20, y^ = 10, n = 1 => MAPE = 50%
Y = 10, y^ = 20, n = 1 => MAPE = 100%
Trend – No Trend, Linear Trend, Quadratic Trend
No trend : 평균값으로 추정 (일정 값) => 신뢰구간 형식으로 interval 구함
Time이 유일한 explanatory 변수일 경우 Least-squared estimation (최소제곱법)으로 사용

보통의 회귀 모델의 경우, error term의 가정은 평균이 0, 분산이 시그마 제곱임, Cov(I,j) = 0인 독립을 따름
시계열의 경우 error term의 가정에서 독립이라는 것이 위배될 가능성이 큼!
Correlation : 두 변수 사이의 관계를 -1~1 사이의 값으로 표현하는 척도
Autocorrelation : 자기자신과 shift된 자기 자신과의 관계 (슬라이딩 윈도우 개념) – residual을 사용
Positive autocorrelation : +가 나오면 그 다음 나오는 것은 + 가 나온다는 관계
Negative autocorrelation, random autocorrelation
Durbin-Watson Test : first order (한시점 미룬) positive auttocorrelation이 있는 지 확인하는 테스트
H0: not autocorrelated
Season Variations – constant, increasing 두개가 있음
Constant seasonal variation : seasonal한 폭이 일정한 경우 (핸들링 쉬움)
Increasing seasonal variation : seasonal 폭이 계속 증가한 경우 (핸들링 어려움) => constant하게 변화시켜줌 (제곱근, 로그 변환 등)

1. Binary Variable Model : 각 달에 해당하면 1 아니면 0으로 설정을 하여 12월을 기준으로 하기에 12월에 해당하는 것은 모든 M이 0이 되면 됨
만일 increasing seasonal variation이 보일 경우 로그 변환이나 제곱근 변화를 시켜줌
Beta2가 양수일 경우, 12월보다 1월에 더 많다는 것을 의미하는 것임


2. Trigonometric Model : 사인과 코사인으로 seasonal을 반영하고자 함
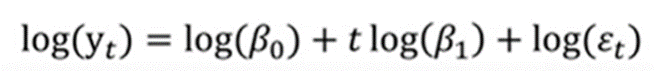
3. Growth Curve Model : 비선형 결합 => 로그를 사용해 선형으로 변경
지수평활법 - y자체의 패턴을 통해서 예측
1. 구간 평균법 : 과거 시점의 일정 기간의 평균으로 다음 시점을 예측
- 일정 기간 N을 결정 =>과거 N 기간 동안의 데이터를 평균 => 예측
- 한계 : 미래의 예측 값이 동일, 과거 n 데이터에 동일한 가중치
- 작은 값의 N은 최근 데이터의 경향을 많이 받고, 큰 값은 과거 데이터 경향을 많이 반영해 편평하게 예측

지수 평활법 : 단순 평균이 아닌 가중 평균을 이용하고 지수분포 모양에 근거한 가중치를 결정 => 최근 데이터에 보다 많은 가중치를 두고 갈수록 가중치가 줄어듦
2. 단순지수 평활법 : 모든 과거데이터 포함해 계산, 최근 데이터에 보다 큰 가중치 부여
- 현재와 가까운 것은 alpha만큼만 곱해지고 점점 더 (1-alpha)만큼의 곱을 해서 작게 만듦
- 큰 alpha => 최근 데이터에 큰 가중치, 작은 alpha => 과거 데이터에 큰 가중치 (보편적으로 0.2나 0.3사용)
- 한계 : 트랜드 있는 데이터에 적합X, 계절적 변동 있는 데이터에 적합X, 미래 시점 관계없이 예측 값 모두 동일

3. 이중지수평활법 : 트랜드가 존재하는 시계열 데이터 예측시 적합, 단순지수평활법을 2번 적용
회귀분석으로 L0(기울기)와 B0 (Y 절편) 결정 후 (1-alpha) 가중치에 Bt가 있다는 점

단순지수 평활법과 다른 점은 Bt 앞 계수가 다르다는 점
4. 홀트-윈터 지수평활법 : 계절변동 존재시 사용 – additive와 multiplicative 두 개가 존재
Additive 방법 – 계절 변동 산포 일정한 경우 사용
Multiplicative 방법 – 계절 변동 산포 증가할 경우 사용
'머신러닝' 카테고리의 다른 글
| 시계열 공부 (2) - ARIMA 모형 (0) | 2023.06.27 |
|---|---|
| Statsmodels 이용한 시계열 분석에 대해 (0) | 2023.05.04 |
| pandas를 이용한 시계열 데이터 처리에 대해 (0) | 2023.05.03 |
| 클러스터링(군집화) 알고리즘에 대해 (1) | 2023.05.01 |
| Pandas에 대해 (Series, DataFrame) (0) | 2023.04.30 |



